Use case 1¶
What data are available to develop a model in a particular watershed?
Problem¶
Building a water resources model to solve water management and planning problems requires acquiring input data that describe the system. In existing practices, once a modeler selects a model and identifies its required types of input data, they manually search for datasets that contain relevant data. Then a modeler manually maps out the term for each attribute in their model with equivalent attributes in other datasets to math them.
Solution¶
This use case shows how a modeler can use WaMDaM extensible Objects, Attributes, and controlled vocabularies to more readily and consistently identify available data from the 13 loaded datasets for WEAP and WASH models. Users can use identified data to expand existing WEAP and WASH model instances in the Lower Bear River Watershed Utah (light red in the Bear River Figure to the entire Watershed (darker red in the Bear River Figure).
First, provide the model name (e.g., Dataset name is WEAP) and a min and max longitudes and latitudes of the study area (e.g., Box that includes Bear River Watershed). Second, execute the use case script that uses the registered controlled vocabularies to search for equivalent Attributes that have data values in all the datasets within the provided boundary. The script also identifies the list of Object Types and Attributes required by the model but do not have available data in WaMDaM database.
For the two models in this use case, the WEAP model has 11 Object Types with 127 Attributes whiles the WASH model has three Object Types with 54 attributes. Using the Reservoir controlled term as a mediator between and the 13 datasets returns all the local native terms: Dam from the US Dams dataset and Reservoir Node from the BRSDM model instance. Similarly, the controlled attribute Volume returns Max_STOR from US Major Dam’s dataset, STORG_ACFT and Capacity from Utah Dams dataset, and Max Storage Capacity from the BRSDM model instance.
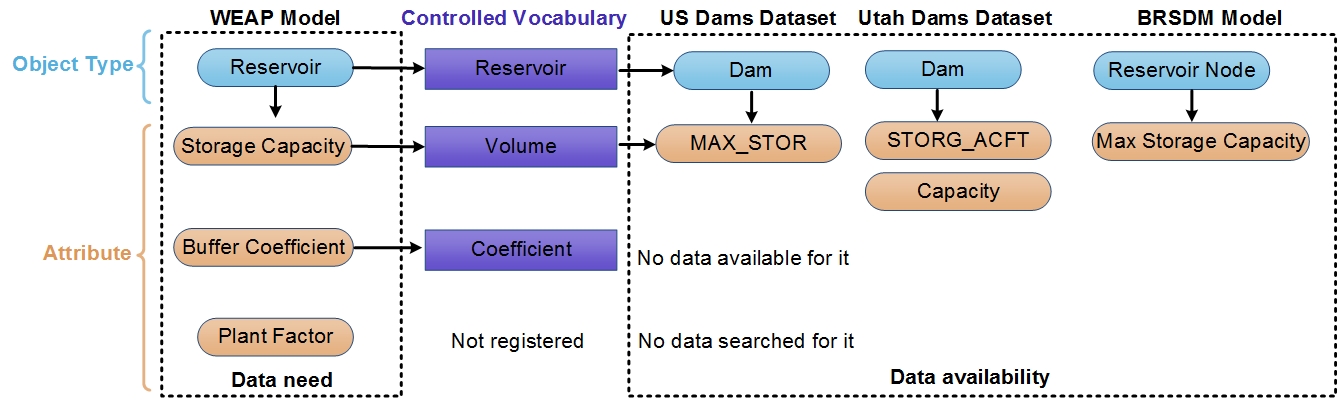 Figure 1: Example conceptual mapping showing how the use of controlled vocabulary can help retrieve different available native attributes in datasets for reservoirs in the WEAP model instance.
Figure 1: Example conceptual mapping showing how the use of controlled vocabulary can help retrieve different available native attributes in datasets for reservoirs in the WEAP model instance.
SQL queries/WEAP Model¶
| Question | Query | Result (CSV) |
|---|---|---|
| Identify model data requirements | script | Result |
| Which attributes have available data | script | Result |
| Where the data is available in datasets | script | Result |
| What additional data are needed | script | Result |
SQL queries/WASH Model¶
| Question | Query | Result (CSV) |
|---|---|---|
| Identify model data requirements | script | Result |
| Which attributes have available data | script | Result |
| Where the data is available in datasets | script | Result |
| What additional data are needed | script | Result |
Results¶
In the query results, WaMDaM shows that five datasets can provide data for 22 attributes in the Bear River WEAP model and there are still 105 attributes that are needed to expand the WEAP model (Table 1). The five datasets are: US Dams Dataset, BRSDM model instance, Utah Dams Dataset, WaDE, and Idaho Flows dataset. Users can also select Categories to narrow their search for available data. For example, searching only for attributes in the Physical and Operational categories and excluding the Water Quality and Cost categories focuses on 65 attributes required in WEAP which reduces the search for the actually needed data in a model instance. The use case also shows that the five data sources can provide for six attributes in the Bear River WASH model while 48 more attributes are still needed. The WASH model uses many ecologic parameters that do not have data values among the datasets in WaMDaM.
Table 1: Summary of data availability to expand WEAP and WASH models in the Bear River Watershed. Full list is available the use cases online page
| Availability | WEAP | WASH |
|---|---|---|
| count of unique attributes | count of unique attributes | |
| Required | 127 | 54 |
| Available | 105 | 6 |
| No data for them | 43 | 48 |
Significance¶
This use case demonstrates how WaMDaM provides a more readily automated and consistent method to identify available (or unavailable) data in multiple datasets that are required by models in a study area. Note that the value of data in WaMDaM increases as far as identifying it for other models, as users add coordinates and register it with controlled vocabulary.